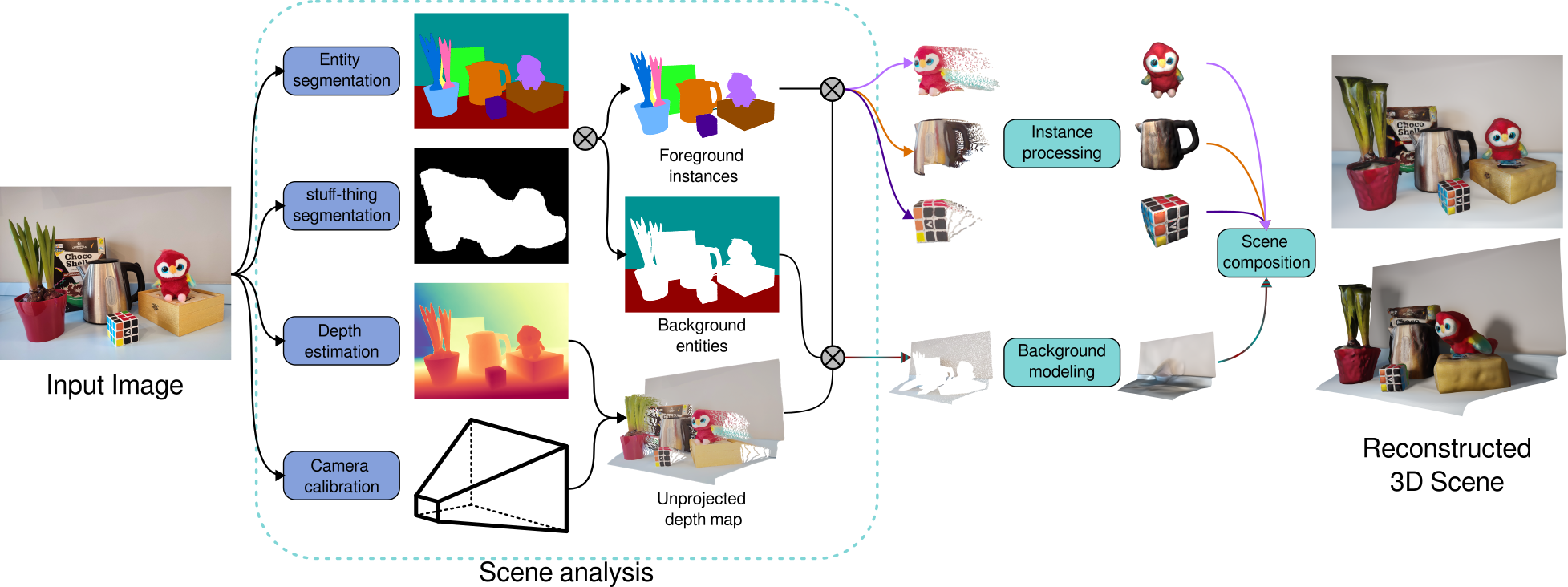
Method
Our method takes as input a single RGB image and predicts the full 3D scene reconstruction represented as a collection of triangle meshes. First, we parse the image of the scene by finding the composing instances, and estimating the depth and camera parameters. Then, we separate the identified entities in stuff (amorphus shapes) and things (characteristic shapes). To recover the full view of each object, we perform amodal completion on the masked crops of the instances. Each object is reconstructed individually in a normalized space and aligned to the view space using the scene layout guides from the depth map. Importantly, we address the differences in focal length, principal point, and camera-to-object distance between the two spaces through reprojection. Finally, we model the background as the surface that approximates the stuff entities collectively.